
今回は前回に引き続き、krewDataでのバックアップと復旧対応について説明します。少し複雑な差分バックアップによる復旧対応のご紹介になりますが最後までお読みいただければ筆者も報われますので、ぜひご一読ください。
差分バックアップでkintone APIの消費を節約!
差分バックアップによる復旧対応では前回ご紹介した全件バックアップによる復旧対応に比べて、取得するレコード数、追加/更新するレコード数を必要最小限に抑えることができるため、kintoneのAPI使用数を抑えることができますし、処理時間を短くできるメリットがあります。
バックアップの目的
ここで一度おさらいになりますが、バックアップは以下の2つの目的を達成するために必要になります。
- 同じ処理結果になるようにデータ編集フローを再実行できること(入力アプリの整合性が保たれていること)

入力アプリの整合性が保たれていないと再実行時の出力データが異なる - データ編集フローを再実行した結果が正しいこと(出力アプリの整合性が保たれていること)

出力アプリの整合性が保たれていないと、出力結果が異なる
このように、入力アプリと出力アプリのデータをエラーが発生した時点の状態に復元し、再度フローを実行した時にデータの整合性を担保できるようにするために、データのバックアップが必要になります。
差分バックアップとは?
そもそも、差分バックアップとはどのようなデータをバックアップすることなのか、イメージできますか?
差分バックアップとは何かを理解していただいた上でバックアップと復元用データ編集フローの作成について読み進めていただいた方が理解し易いと思うので、まずは差分バックアップの考え方について説明します。
例えば、以下のようなデータ編集フロー実行前の出力アプリデータとデータ編集フロー実行後に期待される出力アプリデータがあるとします。(更新キーは「拠点」とします。)

そして、データ編集フロー実行時にエラーが発生し、出力アプリのデータが不整合状態になったとします。

この場合、出力アプリのデータをデータ編集フロー実行前の状態に復元する必要があります。

データ復元への道筋としては、
- 更新対象データをデータ編集フロー実行前の状態に戻す
- 追加対象データを削除する
必要があります。つまり今回の例であれば、
- 名古屋の実績を更新前の値に戻す
- 北海道のレコードを削除する
ことで出力アプリのデータを復元できることになります。
下図では、オレンジ枠で囲ったデータが必要です。このように、更新前の状態にデータを戻すために更新対象の元データと、削除が必要なデータを特定するために追加対象データのみをバックアップすることを差分バックアップと言います。

ただし、以下のケースに限っては、アプリの全データをバックアップすることをお薦めします。
- 入力アプリと出力アプリが同じで、出力方法に「再生成」を設定している場合
「再生成」では、1度出力アプリのデータを全て削除した後に、出力アプリに出力データを追加する処理の流れが実行されます。そのため、上図を例にすると仙台のデータも削除されることになります。
そのため、もしデータを全て削除した後にエラーが発生した場合は、差分バックアップでは復元できないため、全データのバックアップが必要になります。
一方、入力アプリと出力アプリが異なり、出力方法に「再生成」を設定している場合は、データ編集フローでエラーが発生しても、入力アプリのデータは影響を受けず、フローを再実行すれば出力アプリのデータが再作成できます。
バックアップ用データ編集フロー
それでは実際に弊社が公開しているkrewDataの利用例(予実管理フロー)をベースにバックアップ用データ編集フローを見ていきます。

予実管理フローでは「入力アプリ」として予算管理アプリと実績管理アプリを設定し、データを編集した上で最終的に予実一覧アプリにデータを出力しています。

また、「出力アプリ」コマンドでは出力方法「更新」、「更新または追加」のオプションがON、拠点が更新キーに設定されています。更新キーが合致するレコードがあれば出力内容で更新、ない場合は新規レコードとして追加します。
差分バックアップを出力するために、同じフィールド構造 + レコードの状態(更新対象なのか、追加対象なのか)を示すフィールドを追加したバックアップ用アプリを用意し(kintoneのアプリ複製機能が便利です)、そのアプリに今回更新対象になる元の出力アプリのレコードと、今回新たに追加対象になるレコードを出力するデータ編集フローを追加すればOKです。
なお、バックアップ用アプリは、常にクリアな状態である必要があるので、その時の出力方法は「再生成」を設定します。
下図がバックアップ用データ編集フローの全体図です。既存のデータ編集フローを元に構成していきます。

- 出力レコードと既存レコードを結合します。今回の例では拠点をキーに結合します。
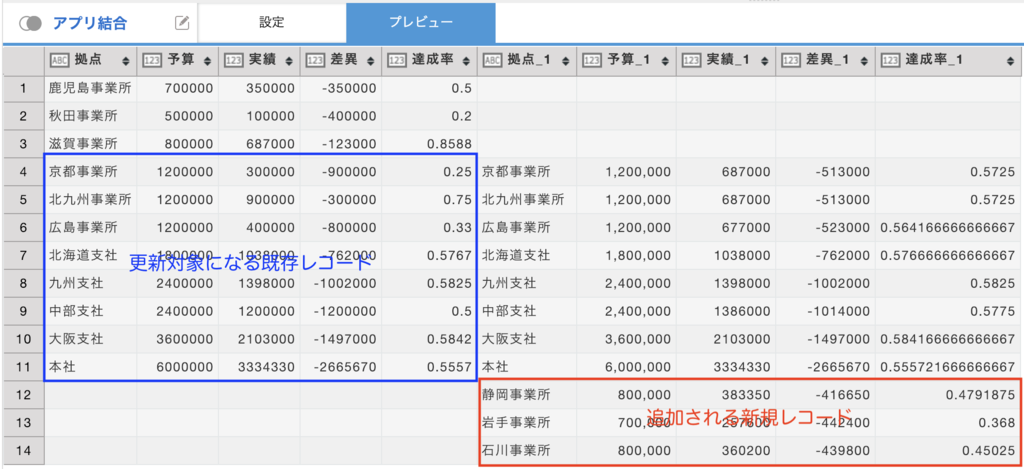
出力レコードと既存レコードの結合 結合方法を「完全外部結合」にすることで更新対象になる既存レコードと、今回のフロー実行で追加される新規レコードをわりだすことができます。
- 結合結果から更新対象になる既存レコードのみを「フィルタ」コマンドで抽出します。抽出後、「フィールド選択」コマンドで必要なフィールドの抜粋と「定数の追加」コマンドでレコードの状態を示すフィールドを追加します。この例では状態は”更新”として登録しています。

更新対象になる既存レコードの抽出 - 結合結果から追加される新規レコードのみを「フィルタ」コマンドで抽出します。先と同じように、抽出後、「フィールド選択」コマンドで必要なフィールドを抜粋と「定数の追加」コマンドでレコードの状態を示すフィールドを追加します。この例では状態は”追加”として登録しています。

追加される新規レコードの抽出 - 最後に「レコード結合」コマンドを使用して、抽出した結果を結合することでバックアップデータの完了です。このデータをバックアップ用のアプリに出力します。

バックアップデータ
復元用データ編集フロー
バックアップしたデータから、不整合状態の出力アプリをデータ編集フロー実行前の状態に復元する、復元用データ編集フローを作成します。

- 既存レコード(不整合)とバックアップデータを結合します。

既存レコード(不整合)とバックアップデータの結合 結合方法を「完全外部結合」にすることで、今回のデータ編集フローで処理対象外だった既存レコードと、削除対象である追加されてしまったレコード、元の値に戻す必要がある更新対象レコードをわりだすことができます。
出力アプリを、エラーになったデータ編集フロー実行前の状態に復元することが目的であるため、実際はエラー前に追加済みだったレコードと、エラー前に更新済みだったレコードを意識する必要はありません。 - 対象外だった既存レコードを「フィルタ」コマンドで抽出します。この時に、復元には不要である、新規追加レコードを除外しています。抽出後、「フィールド選択」コマンドで必要なフィールド(既存の値を使用)を抜粋します。

対象外だった既存レコードの抽出 - 更新対象バックアップレコードを「フィルタ」コマンドで抽出します。抽出後、「フィールド選択」コマンドで必要なフィールド(バックアップされた値を使用)を抜粋します。

更新対象バックアップレコードの抽出 - 最後に「レコード結合」コマンドを使用して、抽出した結果を結合することで復元データの完了です。このデータを復元対象のアプリに出力することで、不整合になる前の状態に戻すことができます。なお、出力方法は「再生成」を設定してください。

復元データ
これで復元用データ編集フローの作成が完了しました。後は、バックアップ用データ編集フローを該当のデータ編集フロー実行前にスケジュールすることでバックアップデータを取得できるようになります。
復元用データ編集フローは、万が一エラーが発生してしまった時に適宜手動でフローを実行し復旧対応を行う形になります。
まとめ
いかがでしたか?2回に渡りお届けしました内容をご参考いただければ、krewDataを使用したバックアップとデータの復元方法をご理解いただけたかなと思います。最後に全件バックアップをお薦めするケースと再実行でデータ復旧が可能なケースについて改めてお伝えします。
- 全件バックアップをお薦めするケース
- 入力アプリと出力アプリが同じで、出力方法を「再作成」に設定している。
- 再実行でデータ復旧が可能なケース
- 入力アプリと出力アプリが異なり、出力方法を「再作成」に設定している
なお、上記以外のケースでは、お客さまのkrewData活用方針にあわせて、全件バックアップで対応するか、差分バックアップで対応するかをお選びいただければと思います。
- krewDataを使ってシンプルに、データの整合性を担保したい場合
=>全件バックアップによる復元 - 複雑なフロー構成に抵抗なし!kintoneのAPI消費を節約しつつ、データの整合性を担保したい場合
=>差分バックアップによる復元
krewDataをお客さまにより安全にお使いいただくためにも、ぜひ今回紹介した対応方法によるkrewData運用もご検討いただければ幸いです。


